
In an investigative foray into face mask detection utilizing YOLOv4, this study has successfully crafted a model with a mAP of 73.62% at an IoU threshold of 0.50. A comprehensive review of contemporary real-time object detection algorithms, including SSD and YOLO variants, established YOLOv4 as the preeminent choice in terms of speed and accuracy, even when juxtaposed with Google's EfficientDet and Facebook’s RetinaNet/MaskRCNN.
The model demonstrated exceptional proficiency in detecting correctly worn face masks, achieving an impressive mAP of 90.08%. It also showed reasonable effectiveness in identifying partially visible faces. However, the detection of improperly worn masks, colloquially termed 'chin diapers,' was less robust, a limitation attributed to the limited diversity in the training dataset. The study suggests that future enhancements could include the development of a more comprehensive dataset and the integration of advanced data augmentation techniques.
Crucially, the study underscores the importance of high accuracy in identifying individuals correctly wearing masks as they are the primary focus for admission into monitored spaces. The ability of the system to flag individuals not wearing masks or wearing them incorrectly is a pivotal feature, analogous to a security officer's role at the entrance.
[Read Full Post]
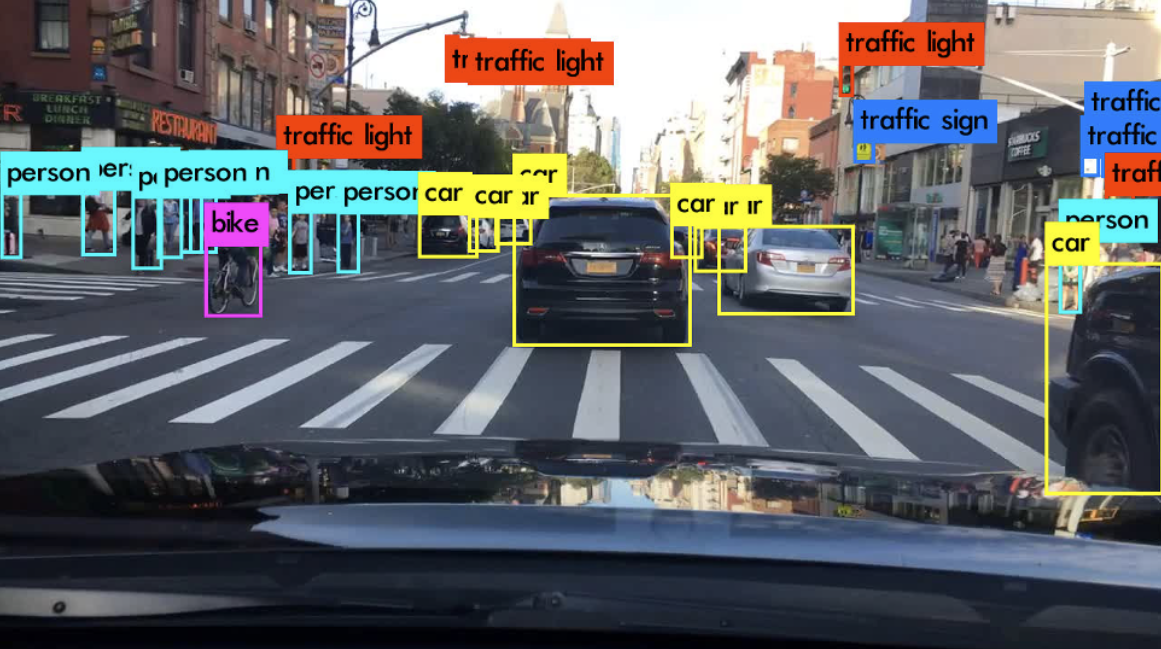
In this project, I conducted an experimental analysis of YOLOv3's capability for real-time object detection, a critical component in autonomous driving systems. After an extensive review and comparison of leading real-time object detection algorithms, including SSD and previous YOLO versions, YOLOv3 emerged as the superior choice in terms of speed and accuracy. However, challenges remain in detecting small objects and addressing class imbalances, as evidenced by YOLOv3's performance on the BDD100k dataset.
While YOLOv3 showed a promising mAP of 15.44 overall, it particularly excelled with a 32.96 AP in detecting cars, albeit with difficulties in recognizing distant vehicles and those obscured by headlights. Pedestrian detection also proved problematic, especially at farther ranges. To improve upon these issues, data augmentation strategies were proposed, with further suggestions to utilize more balanced datasets like KITTI for training.
[Read Full Post]
For this project, I propose an innovative approach to optimize anchor boxes for the state-of-the-art object detection algorithm Single Shot Detector. Traditionally, anchor boxes are predefined in a simplistic, hand-picked manner. For instance, Wei et al. selected anchors with ratios of 1:1, 1:2, 2:1, 1:3, and 3:1, and their implementation of Single Shot Detector 300x300 achieved a 74.3% mAP on the VOC2007 testing set.
To enhance accuracy and streamline the model, my proposal involves using k-means clustering on the ground truth boxes of the VOC2007+VOC2012 training set. This method is aimed at tailoring the anchor boxes more precisely to the data distribution, thereby identifying the most effective number of anchor boxes and their aspect ratios. Through this approach, it was discovered that the number of anchors per grid cell could be reduced from 6 to 4 while still achieving an increase in mAP by 0.7%. This refinement not only improves performance but also makes the model more efficient and data-adaptive.
[Read Full Post]